I’m going to cover a lot of ground in this post, so here’s the TLDR:
- We built a Twitter-scale Mastodon instance from scratch in only 10k lines of code. This is 100x less code than the ~1M lines Twitter wrote to build and scale their original consumer product, which is very similar to Mastodon. Our instance is located at https://mastodon.redplanetlabs.com and open for anyone to use. The instance has 100M bots posting 3,500 times per second at 403 average fanout to demonstrate its scale.
- Our implementation is built on top of a new platform called Rama that we at Red Planet Labs have developed over the past 10 years. This is the first time we’re talking about Rama publicly. Rama unifies computation and storage into a coherent model capable of building end-to-end backends at any scale in 100x less code than otherwise. Rama integrates and generalizes data ingestion, processing, indexing, and querying. Rama is a generic platform for building application backends, not just for social networks, and is programmed with a pure Java API. I will be exploring Rama in this post through the example of our Mastodon implementation.
- We spent nine person-months building our scalable Mastodon instance. Twitter spent ~200 person-years to build and scale their original consumer product, and Instagram spent ~25 person-years building Threads, a recently launched Twitter competitor. In their effort Instagram was able to leverage infrastructure already powering similar products.
- Our scalable Mastodon implementation is also significantly less code than Mastodon’s official implementation, which cannot scale anywhere near Twitter-scale.
- In one week we will release a version of Rama that anyone can download and use. This version simulates Rama clusters within a single process and can be used to explore the full Rama API and build complete prototypes. We will also release the Rama documentation at that time. (Instructions for downloading Rama are now available here and the documentation is available here.)
- In two weeks we will fully open-source our Mastodon implementation (This is now open-source).
- Red Planet Labs will be starting a private beta soon to give companies access to the full version of Rama. We will release more details on the private beta later, but companies can apply here in the meantime (The private beta is over and Rama is now free to use).
We recognize the way we’re introducing Rama is unusual. We felt that since the 100x cost reduction claim sounds so unbelievable, it wouldn’t do Rama justice to introduce it in the abstract. So we took it upon ourselves to directly demonstrate Rama’s 100x cost reduction by replicating a full application at scale in all its detail.
Table of contents
Our Mastodon instance
First off, we make no comment about whether Mastodon should be scalable. There are good reasons to limit the size of an individual Mastodon instance. It is our belief, however, that such decisions should be product decisions and not forced by technical limitations. What we are demonstrating with our scalable Mastodon instance is that building a complex application at scale doesn’t have to be a costly endeavor and can instead be easily built and managed by individuals or small teams. There’s no reason the tooling you use to most quickly build your prototype should be different from what you use to build your application at scale.
Our Mastodon instance is hosted at https://mastodon.redplanetlabs.com. We’ve implemented every feature of Mastodon from scratch, including:
- Home timelines, account timelines, local timeline, federated timeline
- Follow / unfollow
- Post / delete statuses
- Lists
- Boosts / favorites / bookmarks
- Personalized follow suggestions
- Hashtag timelines
- Featured hashtags
- Notifications
- Blocking / muting
- Conversations / direct messages
- Filters
- View followers / following in order (paginated)
- Polls
- Trending hashtags and links
- Search (status / people / hashtags)
- Profiles
- Image/video attachments
- Scheduled statuses
- ActivityPub API to integrate with other Mastodon instances
There’s huge variety between these features, and they require very different kinds of implementations for how computations are done and how indexes are structured. Of course, every single aspect of our Mastodon implementation is scalable.
To demonstrate the scale of our instance, we’re also running 100M bot accounts which continuously post statuses (Mastodon’s analogue of a “tweet”), replies, boosts (“retweet”), and favorites. 3,500 statuses are posted per second, the average number of followers for each post is 403, and the largest account has over 22M followers. As a comparison, Twitter serves 7,000 tweets per second at 700 average fanout (according to the numbers I could find). With the click of a button we can scale our instance up to handle that load or much larger – it would just cost us more money in server costs. We used the OpenAI API to generate 50,000 statuses for the bots to choose from at random.
Since our instance is just meant to demonstrate Rama and costs money to run, we’re not planning to keep it running for that long. So we don’t recommend using this instance for a primary Mastodon account.
One feature of Mastodon that needed tweaking because of our high rate of new statuses was global timelines, as it doesn’t make sense to flood the UI with thousands of new statuses per second. So for that feature we instead show a small sample of all the statuses on the platform.
The implementation of our instance looks like this:

The Mastodon backend is implemented as Rama modules (explained later on this page), which handles all the data processing, data indexing, and most of the product logic. On top of that is our implementation of the Mastodon API using Spring/Reactor. For the most part, the API implementation just handles HTTP requests with simple calls to the Rama modules and serves responses as JSON. We use Soapbox to serve the frontend since it’s built entirely on top of the Mastodon API.
S3 is used only for serving pictures and videos. Though we could serve those from Rama, static content like that is better served via a CDN. So we chose to use S3 to mimic that sort of architecture. All other storage is handled by the Rama modules.
Our implementation totals 10k lines of code, about half of which is the Rama modules and half of which is the API server. We will be fully open-sourcing the implementation in two weeks.
Our implementation is a big reduction in code compared to the official Mastodon implementation, which is built with Ruby on Rails. That codebase doesn’t always have a clear distinction between frontend and backend code, but just adding up the code for clearcut backend portions (models, workers, services, API controllers, ActivityPub) totals 18k lines of Ruby code. That doesn’t include any of the database schema definition code, configurations needed to run Postgres and Redis, or other controller code, so the true line count for the official Mastodon backend is higher than that. And unlike our Rama implementation, it can’t achieve anywhere near Twitter-scale.
This isn’t a criticism of the Mastodon codebase – building products with existing technologies is just plain expensive. The reason we’ve worked on Rama for so many years is to enable developers to build applications much faster, with much greater quality, and to never have to worry about scaling ever again.
Performance and scalability
Here’s a chart showing the scalability of the most intensive part of Mastodon, processing statuses:

As you can see, increasing the number of nodes increases the statuses/second that can be processed. Most importantly, the relationship is linear. Processing statuses is so intensive because of fanout – if you have 15M followers, each of your statuses has to be written to 15M timelines. Each status on our instance is written to an average of 403 timelines (plus additional work to handle replies, lists, and conversations).
Twitter operates at 7,000 tweets per second at 700 average fanout, which is equivalent to about 12,200 tweets / second at 403 average fanout. So you can see we tested our Mastodon instance well above Twitter-scale.
Here’s a chart showing the latency distribution for the time from a status being posted to it being available on follower timelines:
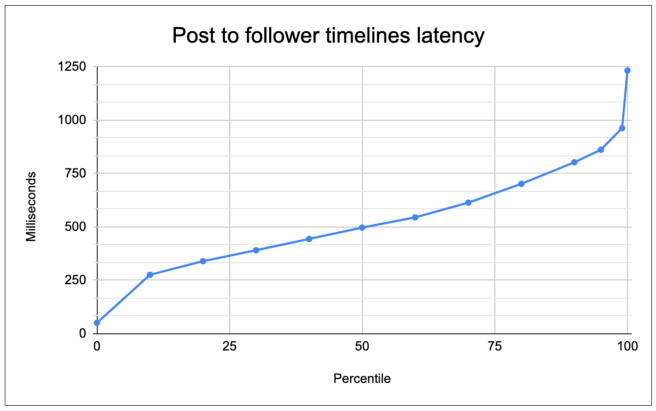
These numbers are a bit better than Twitter’s numbers. Because of how unbalanced the social graph is, getting performance this good and this reliable is not easy. For example, when someone with 20M followers posts a status, that creates a huge burst of load which could delay other statuses from fanning out. How we handled this is described more below.
Lastly, here’s a chart showing the latency distribution for fetching the data to render a user’s home timeline:

Rendering a home timeline requires a lot of data from the backend: a page of statuses to render that aren’t muted/filtered, stats on each status (number of replies, boosts, and favorites), as well as information on the accounts that posted each status (username, display name, profile pic). Getting all this done in an average of 87ms is extremely efficient and a result of Rama being such an integrated system.
Rama
The numbers I’ve shared here should be hard to believe: a Twitter-scale Mastodon implementation with extremely strong performance numbers in only 10k lines of code, which is less code than Mastodon’s current backend implementation and 100x less code than Twitter’s scalable implementation of a very similar product? How is it possible that we’ve reduced the cost of building scalable applications by multiple orders of magnitude?
You can begin to understand this by starting with a simple observation: you can describe Mastodon (or Twitter, Reddit, Slack, Gmail, Uber, etc.) in total detail in a matter of hours. It has profiles, follows, timelines, statuses, replies, boosts, hashtags, search, follow suggestions, and so on. It doesn’t take that long to describe all the actions you can take on Mastodon and what those actions do. So the real question you should be asking is: given that software is entirely abstraction and automation, why does it take so long to build something you can describe in hours?
At its core Rama is a coherent set of abstractions for expressing backends end-to-end. All the intricacies of an application backend can be expressed in code that’s much closer to how you describe the application at a high level. Rama’s abstractions allow you to sidestep the mountains of complexity that blow up the cost of existing applications so much. So not only is Rama inherently scalable and fault-tolerant, it’s also far less work to build a backend with Rama than any other technology.
Let’s now dive into Rama. We’ll start with a high-level overview of Rama’s concepts. Then we’ll look at how some of the most important parts of our Mastodon instance are implemented in terms of these concepts. Finally, we’ll look at some code from our Mastodon implementation.
Rama is programmed entirely with a Java API, and Rama’s programming model has four main concepts:

On the left are “depots”, which are distributed, durable, and replicated logs of data. All data coming into Rama comes in through depot appends. Depots are like Apache Kafka except integrated with the rest of Rama.
Next are "ETL"s, extract-transform-load topologies. These process incoming data from depots as it arrives and produce indexed stores called “partitioned states”. Rama offers two types of ETL, streaming and microbatching, which have different performance characteristics. Most of the time spent programming Rama is spent making ETLs. Rama exposes a Java dataflow API for coding topologies that is extremely expressive.
Next are “partitioned states”, which we usually call “PStates”. PStates are how data is indexed in Rama, and just like depots they’re partitioned across many nodes, durable, and replicated. PStates are one of the keys to how Rama is such a general-purpose system. Unlike existing databases, which have rigid indexing models (e.g. “key-value”, “relational”, “column-oriented”, “document”, “graph”, etc.), PStates have a flexible indexing model. In fact, they have an indexing model already familiar to every programmer: data structures. A PState is an arbitrary combination of data structures, and every PState you create can have a different combination. With the “subindexing” feature of PStates, nested data structures can efficiently contain hundreds of millions of elements. For example, a “map of maps” is equivalent to a “document database”, and a “map of subindexed sorted maps” is equivalent to a “column-oriented database”. Any combination of data structures and any amount of nesting is valid – e.g. you can have a “map of lists of subindexed maps of lists of subindexed sets”. I cannot emphasize enough how much interacting with indexes as regular data structures instead of magical “data models” liberates backend programming.
The last concept in Rama is “query”. Queries in Rama take advantage of the data structure orientation of PStates with a “path-based” API that allows you to concisely fetch and aggregate data from a single partition. In addition to this, Rama has a feature called “query topologies” which can efficiently do real-time distributed querying and aggregation over an arbitrary collection of PStates. These are the analogue of “predefined queries” in traditional databases, except programmed via the same Java API as used to program ETLs and far more capable.
Individually, none of these concepts are new. I’m sure you’ve seen them all before. You may be tempted to dismiss Rama’s programming model as just a combination of event sourcing and materialized views. But what Rama does is integrate and generalize these concepts to such an extent that you can build entire backends end-to-end without any of the impedance mismatches or complexity that characterize and overwhelm existing systems.
All these concepts are implemented by Rama in a linearly scalable way. So if your application needs more resources, you can add them at the click of a button. Rama also achieves fault-tolerance by replicating all data and implementing automatic failover.
Here’s an example of how these concepts fit together. These are all the depots, ETLs, PStates, and query topologies for the portion of our Mastodon implementation handling profiles, statuses, and timelines:

This looks intimidating, but this part of the codebase only totals 1,100 lines of code. And it implements a ton of functionality, all scalably: statuses, timelines, boosts, conversations, favorites, bookmarks, mutes, account registration, profile edits, federation, and more. Notice that the PStates are a diverse collection of data structure combinations, and there are 33 of them here. Many of the ETLs produce multiple PStates and consume multiple depots. Making depots, ETLs, and PStates is inexpensive in Rama and can be done liberally.
What you’re seeing in this diagram is a total inversion of control compared to how applications are typically architected today. For example, consider the “fanout” ETL in this diagram which processes incoming statuses and sends them to follower timelines (you’ll see the code for this later in this post). There are a bunch of rules dictating which statuses go to which followers – boosts never go back to the original author, replies only go to followers who also follow the account being replied to, and so on. Traditionally, that’s accomplished with a “database layer” handling storage and a separate “application layer” implementing the product logic. The “application layer” does reads and writes to the “database layer”, and the two layers are deployed, scaled, and managed separately. But with Rama, the product logic exists inside the system doing the indexing. Computation and storage are colocated. Rama does everything a database does, but it also does so much more.
When building a backend with Rama, you begin with all the use cases you need to support. For example: fetch the number of followers of a user, fetch a page of a timeline, fetch ten follow suggestions, and so on. Then you determine what PState layouts (data structures) you need to support those queries. One PState could support ten of your queries, and another PState may support just one query.
Next you determine what your source data is, and then you make depots to receive that data. Source data usually corresponds to events happening in your application, like “Alice follows Bob”, “James posted the status ‘Hello world’”, or “Bob unfollows Charlie”. You can represent your data however you want, whether Java objects, frameworks like Thrift or Protocol Buffers, or even unstructured formats like JSON (however, we recommend using structured formats as much as possible).
The last step is writing the ETL topologies that convert source data from your depots into your PStates. When deployed, the ETLs run continuously keeping your PStates up to date. Rama’s ETL API, though just Java, is like a “distributed programming language” with the computational capabilities of any Turing-complete language along with facilities to easily control on which partition computation happens at any given point. You’ll see many examples of this API later in this post.
Clusters and modules
Rama is deployed onto a cluster of nodes. There’s a central daemon called the “Conductor” which coordinates deploys, updates, and scaling operations. Every node has a “Supervisor” daemon which manages the launch/teardown of user code.
Applications are deployed onto a Rama cluster as “modules”. A “module” contains an arbitrary combination of depots, ETLs, PStates, and query topologies. Unlike traditional architectures, where the corresponding analogues exist in separate processes and usually on separate nodes, in Rama these are colocated in the same set of processes. This colocation enables fantastic efficiency which has never been possible before. Modules can also consume data from depots and PStates in other modules just as easily as they can from their own. A module runs forever, continuously processing new data from depots, unless you choose to destroy it.
A module is deployed by giving the Conductor a .jar file with user code. Additionally, configuration is provided for the number of nodes to allocate to the module, replication parameters, as well as any other tuning parameters. A module is updated a similar way: a new .jar is provided with the new code, and the Conductor orchestrates an update sequence that launches new processes and transfers depots and PStates to the new module version.
Here’s what a Rama cluster could look like with two modules deployed, “SocialGraphModule” and “TimelineModule”:

For testing and development, Rama provides a class called
InProcessCluster
for simulating Rama clusters within a single process.
Mastodon on Rama
Let’s look at some of the key parts of how Mastodon is implemented on top of Rama. In this section we’ll focus on the design of Mastodon – what PStates are created, the flow of how data is processed, and how everything is organized. You’ll see how Rama’s capabilities enable some seriously novel ways to architect applications. In the next section we’ll look at some of the code from our implementation.
Following hashtags
Let’s start with an extremely simple part of the implementation, tracking followers for hashtags. The implementation for this totals 11 lines of code and supports the following queries:
- Does user A follow hashtag H?
- Who follows hashtag H (paginated)?
- How many followers does hashtag H have?
Only a single PState is needed for this, called
$$hashtagToFollowers
(PState names in Rama always begin with
$$
). It is a map from a hashtag to a set of account IDs. Here’s a visualization of what this PState could look like across two partitions. Keep in mind that PStates are distributed across many partitions, with each partition of a PState being the specified data structure:

There are two events that change this PState: following a hashtag, and unfollowing a hashtag. In our implementation, these are represented by the types
FollowHashtag
and
RemoveFollowHashtag
.
A good way to visualize how data is processed to produce this PState is via a dataflow graph, as you can see how data moves from the start of processing (one or more depots) to the end results of processing (updates to PStates):

The logic here is trivial, which is why the implementation is only 11 lines of code. You don’t need to worry about things like setting up a database, establishing database connections, handling serialization/deserialization on each database read/write, writing deploys just to handle this one task, or any of the other tasks that pile up when building backend systems. Because Rama is so integrated and so comprehensive, a trivial feature like this has a correspondingly trivial implementation.
You may be wondering why the follow and unfollow events go onto the same depot instead of separate depots. Though you could implement it that way, it would be a mistake to do so. Data is processed off a depot partition in the order in which it was received, but there are no ordering guarantees across different depots. So if a user was spamming the “Follow” and “Unfollow” buttons on the UI and those events were appended to different depots, it’s possible a later unfollow could be processed before a prior follow. This would result in the PState ending up in the incorrect state according to the order by which the user made actions. By putting both events in the same depot, the data is processed in the same order in which it was created.
As a general rule, Rama guarantees local ordering. Data sent between two points are processed in the order in which they were sent. This is true for processing data off a depot, and it’s also true for intra-ETL processing when your processing jumps around to different partitions as part of computation.
This dataflow diagram is literally how you program with Rama, by specifying dataflow graphs in a pure Java API. As you’ll see below, the details of specifying computations like this involve variables, functions, filters, loops, branching, and merging. It also includes fine-grained control over which partitions computation is executing at any given point.
Social graph
Let’s now look at a slightly more involved part of the implementation, the social graph. The social graph totals 105 lines of code and supports the following queries which power various aspects of Mastodon:
- Does user A follow user B?
- How many followers does user A have?
- How many accounts does user A follow?
- Who are user A’s followers in the order in which they followed (paginated)?
- Who does user A follow in the order in which they followed them (paginated)?
- Who is currently requesting to follow user A in the order in which they requested (paginated)?
- Does user A block user B?
- Does user A mute user B?
- Does user A wish to see boosts from user B?
Even though the implementation is so simple with Rama, it’s worth noting that Twitter had to write a custom database from scratch to build their scalable social graph.
There are four main PStates produced by our social graph implementation, named
$$followerToFollowees
,
$$followeeToFollowers
,
$$accountIdToFollowRequests
, and
$$accountIdToSuppressions
. The first three PStates have the same structure, which is a map from account ID to a linked set of account IDs plus additional information needed about the relationship. For example, for
$$followeeToFollowers
we track whether a follower wants to see boosts from that account in their home timeline (which is one of Mastodon’s features). This PState is also used to compute: whether an account already follows another account, the order in which accounts were followed (which is why a linked set is used rather than a regular set), and the number of followers for an account (which is just the size of the inner set, something Rama computes in fast constant time even if the set has millions of elements).
The
$$accountIdToSuppressions
PState tracks blocks and mutes for each account and has a different structure. It is a map from account ID to a map containing two keys: “blocked” and “muted”. The “blocked” key maps to the set of account IDs the top-level account ID has blocked. The “muted” key is similar but stores a map from account ID to the options for that mute (like expiration time). This PState is used wherever statuses are rendered (e.g. home timeline, notifications) to filter out statuses a user doesn’t want to see.
Here’s a visualization of what the
$$followeeToFollowers
PState could look like in a deployed module:

Here you can see that account “1” is followed by accounts “2”, “7”, and “5”, with “2” and “5” having boosts enabled and “7” having boosts disabled. Account “4” is only followed by account “1”, and “1” has boosts enabled for that relationship.
The social graph is constructed based on follow, unfollow, block, unblock, mute, and unmute events. In Mastodon’s design, blocking a user also unfollows in both directions (if currently followed). So the block and unblock events go on the same depot as the follow-related events, while the mute and unmute events go on a separate depot.
Here’s the dataflow graph showing how these PStates are computed based on the source data:

This is more involved than the hashtag follows dataflow graph since this ETL supports so many more features. Yet it’s still only 105 lines of code to implement. You can see how this ETL makes use of conditionals, branching, and merging in its implementation. Here’s a few notes on the logic within this ETL:
- When a user follows another user, the
$$followerToFolloweesand$$followeeToFollowersPStates are updated. Unfollowing updates the same PStates but removes the relationship instead of adding it. - Blocking is handled specially by implicitly emitting additional unfollow events as part of processing (to unfollow in both directions), as well as tracking who blocks who in the
$$accountIdToSuppressionsPState. - A locked account (where each follower must be individually approved) receives
FollowLockedAccountevents, and unlocked accounts receiveFollowevents. - Attributes of a relationship (e.g. “show boosts”, “notify”) are updated via appending another
FolloworFollowLockedAccountevent to the depot. This is why theFollowLockedAccountchecks if the follow relationship already exists so it can determine whether to update the follow relationship or add a new follow request. - A
Followevent also removes the corresponding follow request if it exists. This is why anAcceptFollowRequestevent just converts to aFollowevent.
This ETL interacts with many PStates at the same time. Because of Rama’s integrated nature, these PStates are colocated with one another within the same processes that are executing the ETL logic. So whereas you always have to do a network operation to access most databases, PState operations are local, in-process operations with Rama ETLs. As you’ll see later, you utilize the network in an ETL via “partitioner” operations to get to the right partition of a module, but once you’re on a partition you can perform as many PState operations to as many colocated PStates as you need. This is not only extremely efficient but also liberating due to the total removal of impedance mismatches that characterizes interacting with databases.
Computing and rendering home timelines
Next let’s look at the core of Mastodon, computing and rendering home timelines. This powers the primary page of the Mastodon experience:

This use case is a great example of how to think about building data-intensive systems not just with Rama, but in general. For any backend feature you want to implement, you have to balance what gets precomputed versus what gets computed on the fly at query-time. The more you can precompute, the less work you’ll have to do at query-time and the lower latencies your users will experience. This basic structure looks like this:

This of course is the programming model of Rama you’ve already seen, and a big part of designing Rama applications is determining what computation goes in the ETL portion versus what goes in the query portion. Because both the ETL and query portions can be arbitrary distributed computations, and since PStates can be any structure you want, you have total flexibility when it comes to choosing what gets precomputed versus what gets computed on the fly.
It’s generally a good idea to work backwards from the needed queries to learn how to best structure things. In the case of querying for a page of a timeline, you need the following information:
- Content for each status
- Stats for each status (number of replies, boosts, and favorites)
- Information about the account that posted each status (username, display name, profile pic)
- Whether the author of each status is blocked or muted
- For boosts, the username of the booster
- ID to use to fetch the next page of statuses
Since statuses can be edited and profile information can be changed, almost all this information is dynamic and must be fetched for each render of a timeline page.
Let’s consider a typical way to go about this with non-Rama technologies, even scalable ones, which unfortunately is extremely inefficient:
- Fetch the list of status IDs for a page of the timeline
- In parallel, send database requests to fetch:
- Content for each status
- Stats for each status
- Information for each author
For a page of 20 statuses, this could easily require over 100 database calls with a lot of overhead in the sheer amount of back and forth communication needed to fetch data from each database partition.
We handled this use case with Rama by making use of Rama’s facilities for colocation of PStates. The module is organized such that all information for a status and the account who posted it are colocated in the same process. So instead of needing separate requests for status content, status stats, and author information, only one request is needed per status.
Structuring the PStates
Here are all the depots, PStates, and query topologies in the module implementing timelines and profiles (repeated from above):

Let’s look at these PStates in closer detail, as the way they’re structured and partitioned is extremely interesting. Let’s start with
$$accountIdToAccount
. This is a map from account ID to profile information, including username, display name, and profile pic. Here’s a picture of what this PState could look like across four partitions:

This PState is partitioned by the account ID. When I say “partitioned by”, I mean how the Mastodon implementation chooses on which partition to store data for any particular account. The most common way to partition a PState is to hash a partitioning key and modulo the hash by the number of partitions. This deterministically chooses a partition for any particular partitioning key, while evenly spreading out data across all partitions (this “hash/mod” technique is used by most distributed databases). For this PState, the partitioning key is the same as the key in the map, the account ID (as you’ll see soon, it doesn’t have to be).
Next is
$$accountIdToStatuses
. This is a map from account ID to a map from status ID to a list of status content versions. A list of status content versions is stored to capture the edit history of a status, which Mastodon lets you view in its UI. You can visualize this PState like so:

Whenever a status is edited, a new version is prepended to its respective inner list. Since this PState and
$$accountIdToAccount
are in the same module, each partition is colocated on the same thread within the same process. You can visualize this colocation like so:

Because of this colocation queries can look at the partitions for both PStates at the same time within the same event instead of needing two roundtrips. You can also have multiple threads per worker process, or multiple worker processes per node.
Now let’s see how things get really interesting.
$$statusIdToFavoriters
is a map from a status ID to a linked set of account IDs. Here’s a visualization of this PState:

Similar to the social graph PStates, this PState is used to compute: the order in which accounts favorited a status (paginated), whether a particular account already favorited a status, and the number of favorites for a status.
What’s interesting is how this PState is partitioned. It is not partitioned by the status ID, which is the key of the map. It is instead partitioned by the account ID of the user who posted that status, which is not even in the map! This same partitioning scheme is used for all other PStates tracking status information, like
$$statusIdToReplies
,
$$statusIdToBoosters
, and
$$statusIdToMuters
. This means all information for a user and all information for that user’s statuses exist on the same partition, and performing a query to fetch all the information needed to render a status only needs to perform a single roundtrip.
Here’s a visualization of how all the PStates described could exist in a module deployment:

Notice, for example, how status ID “3” for account ID “10” exists both as a subvalue within
$$accountIdToStatuses
and also as a top-level key for the status-specific states on the same partition.
This use case is a great example of the power of Rama’s integrated approach, achieving incredible efficiency and incredible simplicity. Each of these PStates exists in exactly the perfect shape and partitioning for the use cases it serves.
Home timelines
Next, let’s explore how home timelines are stored. Materializing home timelines is by far the most intensive part of the application, since statuses are fanned out to all followers. Since the average fanout on our instance is 403, there are over 400x more writes to home timelines than any of the other PStates involved in processing statuses.
PStates are durable, replicated, high-performance structures. They are easy to reason about and ideal for most use cases. In our initial implementation of Mastodon, we stored home timelines in a PState and it worked fine.
However, writing to the home timelines PState was clearly the overwhelming bottleneck in the application because of the sheer amount of data that had to be written to disk and replicated. We also realized that home timelines are unique in that they are somewhat redundant with other PStates. You can reconstruct a home timeline by looking at the statuses of everyone you follow. This can involve a few hundred PState queries across the cluster, so it isn’t cheap, but it’s also not terribly expensive.
As it turns out, what we ended up doing to optimize home timelines is very similar to how Twitter did it for their chronological timelines, and for the exact same reasons. In our revised implementation, we store home timelines in-memory and unreplicated. So instead of needing to persist each timeline write to disk and replicate it to followers, a timeline write is an extremely cheap write to an in-memory buffer. This optimization increased the number of statuses we could process per second by 15x.
Solely storing the timeline in-memory is not sufficient though, as it provides no fault-tolerance in the event of a power loss or other node failure. So a new leader for the partition would not have the timeline info since it’s unreplicated and not persisted to disk. To solve this, we reconstruct the timeline on read if it’s missing or incomplete by querying the recent statuses of all follows. This provides the same fault-tolerance as replication, but in a different way.
Implementing fault-tolerance this way is a tradeoff. For the benefit of massively reduced cost on timeline write, sometimes reads will be much more expensive due to the cost of reconstructing lost timelines. This tradeoff is overwhelmingly worth it because timeline writes are way, way more frequent than timeline reads and lost partitions are rare.
Whereas Twitter stores home timelines in a dedicated in-memory database, in Rama they’re stored in-memory in the same processes executing the ETL for timeline fanout. So instead of having to do network operations, serialization, and deserialization, the reads and writes to home timelines in our implementation are literally just in-memory operations on a hash map. This is dramatically simpler and more efficient than operating a separate in-memory database. The timelines themselves are stored like this:
1 2 3 4 5 | public static class Timeline { public long[] buffer; public int startIndex = 0; // index within buffer that contains oldest timeline element public int numElems = 0; // number of elements in this timeline } |
To minimize memory usage and GC pressure, we use a ring buffer and Java primitives to represent each home timeline. The buffer contains pairs of author ID and status ID. The author ID is stored along with the status ID since it is static information that will never change, and materializing it means that information doesn’t need to be looked up at query time. The home timeline stores the most recent 600 statuses, so the buffer size is 1,200 to accommodate each author ID and status ID pair. The size is fixed since storing full timelines would require a prohibitive amount of memory (the number of statuses times the average number of followers).
Each user utilizes about 10kb of memory to represent their home timeline. For a Twitter-scale deployment of 500M users, that requires about 4.7TB of memory total around the cluster, which is easily achievable.
The in-memory home timelines and other PStates are put together to render a page of a timeline with the following logic:
- First, query the in-memory home timeline to fetch a page of
[author ID, statusID]pairs. - Next, invoke a query topology (a predefined distributed query) that takes in a list of
[author ID, statusID]pairs and returns all information needed to render each status – status content, status stats, and author information. The query topology goes to all partitions containing requested status IDs in parallel and fetches all needed information with colocated PState queries.
Implementing fanout
So that’s the story on how timelines are rendered, but how are home timelines and these various PStates computed? If you look back at the performance numbers, you can see our Mastodon implementation has high throughput that scales linearly while also having great, consistent latencies for delivering statuses to follower timelines.
Let’s focus on how statuses are handled, particularly how timelines are materialized. Whenever someone posts a status, that status must be fanned out to all followers and appended to their home timelines.
The tricky part is dealing with bursty load arising from how unbalanced the social graph can get. In our Mastodon instance, for example, the average fanout is 403, but the most popular user has over 22M followers. 3,500 statuses are posted each second, meaning that every second the system usually needs to perform 1.4M timeline writes to keep up. But if a user with 20M followers posts a status, then the number of timeline writes blows up by 15x to about 21.4M. With a naive implementation this can significantly delay other statuses from reaching follower timelines. And since the latency from posting a status to it reaching follower timelines is one of the most important metrics for this product, that’s really bad!
This is essentially a problem of fairness. You don’t want very popular users to hog all the resources on the system whenever they post a status. The key to solving this issue is to limit the amount of resources a status from a popular user can use before allocating those resources to other statuses. The approach we take in our implementation is:
- For each iteration of timeline processing, fan out each status to at most 64k followers.
- If there are more followers left to deliver to for a status, add that status to a PState to continue fanout in the next iteration of processing.
With this approach a status from a user with 20M followers will take 312 iterations of processing to complete fanout (about 3 minutes), and fairness is achieved by giving all statuses equal access to resources at any given time. Since the vast majority of users have less than 64k followers, most users will see their statuses delivered in one iteration of processing. Statuses from popular users take longer to deliver to all followers, but that is the tradeoff that has to be made given that the amount of resources is fixed at any given time.
As a side note, Twitter also has special handling for users with lots of followers to address the exact same issue.
With the basic approach understood, let’s look specifically at how statuses are processed in our implementation to materialize timelines. Here’s a dataflow diagram showing the logic:

This dataflow diagram is a little bit different than the social graph one, as this ETL is implemented with microbatching while the social graph is implemented with streaming. Streaming processes data directly off of depots as it arrives, while microbatching processes data in small batches. “Start iteration” in this diagram signifies the beginning of a microbatch. The tradeoffs between streaming and microbatching are too much to cover for this post, but you’ll be able to learn more about that next week when we release the documentation for Rama.
In this diagram you can see all the steps involved in delivering statuses to followers. There are many product rules implemented here, such as: only fan out statuses with the correct visibility, only send replies to followers who also follow the account being replied to, respect “show boost” settings, and so on.
This dataflow diagram only shows the computation of home timelines, whereas in reality this ETL also handles lists, hashtag timelines, and conversations. Those all work similarly to home timelines and are just additional branches of dataflow computation with slightly differing logic.
Processing skew from unbalanced social graph
Fairness issues aren’t the only problem caused by an unbalanced social graph. Another problem is skew: a naive implementation that handles all fanout for a single user from a single partition will lead to some partitions of a module having a lot more overall work to do than others. Without balanced processing, throughput is lowered since some resources are idle while others are being overwhelmed.
In our Mastodon implementation, we put significant effort into balancing fanout computation regardless of how unbalanced a social graph gets. This is a deep topic, so we will explore this further in a subsequent blog post. The optimizations we did in this area increased throughput by about 15%.
Personalized follow suggestions
Let’s now look at another part of Mastodon which works completely differently than timelines: personalized follow suggestions. This powers this section on Mastodon:

Everything about how data is processed and indexed for follow suggestions is different from what we looked at in the previous sections. Taken together, the implementations of timelines, the social graph, and follow suggestions demonstrate how expressive Rama is as a system. This generality is a result of the total arbitrariness with which you can write ETL computations, structure indexes, and compute queries.
Unlike the social graph and timelines, the behavior of personalized follow suggestions could be specified in very different ways. We’ve chosen to determine follow suggestions like so:
- Rank accounts to suggest based on who’s most followed by the accounts you already follow
- Don’t suggest accounts you already follow
- If this doesn’t produce enough suggestions (e.g. because you don’t follow many accounts yet), suggest the most followed accounts on the platform
We took a different approach than Mastodon for follow suggestions – the API docs describe follow suggestions as “Accounts that are promoted by staff, or that the user has had past positive interactions with, but is not yet following.” We chose our approach because it’s much more difficult to implement and thus a better demonstration of Rama. Our implementation of personalized follow suggestions totals 141 lines of code.
The main PState underlying follow suggestions is called
$$whoToFollow
, a map from account ID to a list of up to 80 account ID suggestions. The interesting part of the follow suggestions implementation is how this PState is computed and maintained.
Follow suggestions can’t be computed fully incrementally, at least not practically. That is, you can’t receive a new follow or unfollow event and incrementally update all the follow suggestions for affected accounts. Computing follow suggestions is a batch operation that needs to look at everyone an account follows, and everyone they follow, at the same time in a single computation.
With that in mind, there are a few pieces to our implementation. First, everyone’s follow suggestions are recomputed on a regular basis. The ETL for follow suggestions recomputes the suggestions for 1,280 accounts every 30 seconds. Since there are 100M accounts, this means each account has its suggestions updated every 27 days.
In addition to this, we have special handling for new users. When a new user signs up, you want to provide good follow suggestions as soon as possible in order to increase engagement and increase the chance they’ll continue to use the service. So you don’t want to wait 27 days to compute personalized suggestions for a new user. At the same time, you can’t produce good personalized suggestions until the user has followed at least a few accounts. So our implementation tracks milestones which trigger immediate recomputation of follow suggestions: when a user follows 10 accounts and when a user follows 100 accounts.
Structuring the PStates
Here are all the depots, PStates, and query topologies related to the follow suggestions implementation:

Notice that this ETL also consumes
followAndBlockAccountDepot
, which is the same depot as consumed by the social graph ETL to produce the social graph PStates. Depots are sources of truth that can be consumed by as many topologies as you need.
Here’s what each PState for follow suggestions is used for:
-
$$whoToFollow: As described above, this stores a list of up to 80 suggestions for each user. -
$$nextId: This keeps track of the next group of accounts for which to recompute follow suggestions. This stores aLongon each partition that points to a key within the colocated$$followerToFolloweesPState partition. -
$$followCounts: This is a map from account ID to the number of follow actions that account has taken. This is used to track when a user has passed 10 or 100 follows and trigger an immediate recompute of their follow suggestions. -
$$forceRecomputeUsers: This is the set of users (a set per partition) that have recently passed the 10 or 100 follows milestone. Accounts chosen for follow suggestion recomputes come from this PState as well as where$$nextIdis pointing in$$followerToFollowees. -
$$topFollowedUsers: This is a global list of the top followed users on the platform. These are used to supplement a user’s follow suggestions when not enough are computed via the personalized method.
Notice how some of these PStates are not maps at the top-level, which may feel unusual given that pretty much every database that’s ever existed is map-based (with a “key” being the central concept to identify a record or row). But just as data structures other than maps are useful for everyday programming, data structures other than maps are useful for backend programming as well.
Computing follow suggestions
Let’s explore in more detail how follow suggestions are recomputed. Unlike the other ETLs we’ve described, this one initiates computations based on time and not on the receipt of data. Every 30 seconds it needs to recompute follow suggestions for a rotating subset of all users and for any users specified in the
$$forceRecomputeUsers
PState.
You can think of time as an infinite stream of events, with each event being an instant in time. Rama exposes a special depot for time called a “tick depot” which emits events according to a specified frequency.
For follow suggestions, a tick depot is used to trigger processing every 30 seconds. The subsequent computation then uses the PStates described to recompute follow suggestions for a subset of users. The dataflow looks like this:

The key PState is
$$followerToFollowees
. The ETL selects a subset of the keys in that map for processing, and it stores the last key chosen in
$$nextId
. The next iteration will start from that key. When it gets to the end of the PState, it starts over again from the beginning.
The rest of the processing uses
$$followerToFollowees
to fetch follows, fetch the follows of those follows, and aggregate a list of candidates along with how many times each candidate is followed among that subset of users. After filtering out candidates the starting account already follows, the
$$whoToFollow
PState is updated.
Every step of this is done in parallel. So when a subset of users is selected from
$$followerToFollowees
, it’s actually selecting a subset of users from each partition of that PState.
In between recomputes, a user may have followed some of the users in their list of suggestions. This is handled with a query topology that filters a user’s follow suggestions to exclude users they already follow.
DevOps with Rama
Let’s briefly take a look at how we do DevOps with Rama: managing the deployment, monitoring, and operation of modules in production. Since the steps are the same for all modules, we’ll use as an example how we manage the module handling statuses, timelines, and profiles. The module is implemented in the class
com.rpl.mastodon.modules.Core
and is deployed to a Rama cluster like so:
1 2 3 4 5 6 7 8 9 | rama deploy \ --action launch \ --jar target/mastodon.jar \ --module com.rpl.mastodon.modules.Core \ --tasks 128 \ --threads 32 \ --workers 16 \ --replicationFactor 3 \ --configOverrides overrides.yaml |
This submits the module and its code to the cluster with the given parallelism, and Rama then launches worker processes around the cluster to run the module. The same cluster is shared by all modules. Once the workers finish starting up, they start reading from depots, executing ETLs, updating PStates, serving query requests, and so on.
The “replication factor” specifies to how many nodes each depot and PState should replicate its data. Replication happens completely behind the scenes and provides automatic failover in case of failures (e.g. hardware issues). Rama provides very strong guarantees with replication – data is not made visible for consumption from depots or PStates until it has been successfully replicated.
The referenced
overrides.yaml
file has only two lines and just registers with Rama how to serialize/deserialize the custom types used by our implementation (defined using Thrift, described more below).
After the module finishes launching, the Cluster UI for Rama starts displaying telemetry on the module:







Rama tracks and displays telemetry for the module as a whole, as well as specific telemetry for each topology, depot, and PState. The telemetry is extremely useful for understanding the performance of a module and when it needs to be scaled. Rama uses itself to implement telemetry – a built-in module collects telemetry data from all modules into a depot, processes that data with an ETL, and indexes the results into PStates arranged in a time-series structure.
When we want to update the module to add a feature (e.g. add a new PState) or fix a bug, we run a command like the following:
1 2 3 4 5 | rama deploy \ --action update \ --jar target/mastodon.jar \ --module com.rpl.mastodon.modules.Core \ --configOverrides overrides.yaml |
This launches a carefully coordinated automated procedure to launch new worker processes and handoff responsibility for depots and PStates to the new version of the module. Clients of the module doing depot appends and PState queries don’t need to be updated and automatically transition themselves to the new module version.
Similarly, when we want to scale the module to have more resources, we run a command like the following:
1 2 3 | rama scaleExecutors \ --module com.rpl.mastodon.modules.Core \ --workers 24 |
This launches a similar procedure as module update to transition the module to the new version.
And that’s all there is to DevOps with Rama – it’s just a few commands at the terminal to manage everything. You don’t need to invest huge amounts of time writing piles of shell scripts to coordinate changes across dozens of systems. Since Rama is such a cohesive, integrated system it’s able to automate deployment entirely, and it’s able to provide deep and detailed runtime telemetry without needing to lift a finger.
Simple Rama code example
Let’s look at some code! Before diving into the Mastodon code, let’s look at a simple example of coding with Rama to gain a feeling for what it’s like.
I’m not going to explain every last detail in this code – the API is so rich that it’s too much to explain for this post. Instead, I’ll do my best to summarize what the code is doing. In one week we will be releasing all the documentation for Rama, and this includes a six part tutorial that gently introduces everything. We will also be releasing a build of Rama that anyone can download and use. This build will be able to simulate Rama clusters within a single process but will not be able to run distributed clusters. It has the full Rama API and can be used to experiment with Rama. Once we open-source our Mastodon implementation in two weeks, you’ll be able to run it within a single process using this build.
With that said, let’s look at a simple example. Here’s the complete definition for a “word count module”, which accepts sentences as input and produces a single PState containing the count of all words in those sentences:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | public class WordCountModule implements RamaModule { @Override public void define(Setup setup, Topologies topologies) { setup.declareDepot("*sentenceDepot", Depot.random()); StreamTopology wordCount = topologies.stream("wordCount"); wordCount.pstate("$$wordCounts", PState.mapSchema(String.class, Long.class)); wordCount.source("*sentenceDepot").out("*sentence") .each((String sentence, OutputCollector collector) -> { for(String word: sentence.split(" ")) { collector.emit(word); } }, "*sentence").out("*word") .hashPartition("*word") .compoundAgg("$$wordCounts", CompoundAgg.map("*word", Agg.count())); } } |
This module has one ETL named
wordCount
, one depot named
*sentenceDepot
, and one PState named
$$wordCounts
. The ETL receives new sentences from the depot, tokenizes those sentences into words, and then updates the counts for those words in the PState. The PState partitions are updated within a few milliseconds of appending a sentence to the depot.
A module implements the interface
RamaModule
that has a single method
define
on it.
setup
is used to declare depots and any dependencies to depots or PStates in other modules, and
topologies
is used to declare all ETL and query topologies.
The first line of
define
declares the depot. Depot names always begin with a
*
. Strings beginning with
*
are interpreted as variables in Rama code, and they can be passed around and used just like variables in any programming language. The second argument
Depot.random()
specifies the partitioning scheme of the depot. In this case the partitioning scheme causes appended sentences to go to a random partition of the depot. When local ordering is important, like for follow and unfollow events, the partitioning scheme would be set appropriately so events for the same entity go to the same partition.
The next line declares the ETL
wordCount
as a streaming topology.
After that is the declaration of the PState
$$wordCounts
. The PState is declared with a schema that specifies what it stores and how it stores it. In this case it’s just a simple map, but you can specify whatever structure you want here (e.g. a map of subindexed maps of lists of subindexed sets).
Lastly is the definition of the ETL. The line
wordCount.source("*sentenceDepot").out("*sentence")
subscribes the ETL to
*sentenceDepot
and binds any new sentences received to the variable
*sentence
.
The next line tokenizes each sentence into words. Java code is inserted with a lambda to split each sentence on whitespace and emit each word individually as the variable
*word
. Inserting arbitrary Java code into topologies like this is extremely common.
The next line
.hashPartition("*word")
relocates the dataflow to the partition of the module storing the counts for that word. The code before that line and after that line can execute on different machines, and Rama takes care of all the serialization and network transfer involved in moving the computation.
Finally, now that the computation is on the correct partition, the last line updates the count for the word in the PState. This PState update is specified in the form of an aggregation template – in this case it says it’s aggregating a map where the key is the word and the value is the count of all events seen for that word.
This is such a basic example that it doesn’t really do justice to the expressive power of Rama. However, it does demonstrate the general workflow of declaring modules, depots, PStates, and topologies. Some of the functionality not shown here includes: consuming depots/PStates from other modules, query topologies, microbatching, branching/merging, joins, loops, shadowing variables, conditionals, and decomposing code with macros.
Let’s now take a look at interacting with Rama modules as a client outside the cluster, similar to how you interact with a database using a database client. Here’s code that connects to a remote cluster, creates handles to the depot and PState of the module, appends some sentences, and then does some PState queries:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | Map config = new HashMap(); config.put("conductor.host", "1.2.3.4"); RamaClusterManager manager = RamaClusterManager.open(config); Depot depot = manager.clusterDepot("rama.examples.wordcount.WordCountModule", "*sentenceDepot"); depot.append("hello world"); depot.append("hello world again"); depot.append("say hello to the planet"); depot.append("red planet labs"); PState wc = manager.clusterPState("rama.examples.wordcount.WordCountModule", "$$wordCounts"); System.out.println("'hello' count: " + wc.selectOne(Path.key("hello"))); System.out.println("'world' count: " + wc.selectOne(Path.key("world"))); System.out.println("'planet' count: " + wc.selectOne(Path.key("planet"))); System.out.println("'red' count: " + wc.selectOne(Path.key("red"))); |
RamaClusterManager
is used to connect to a cluster and retrieve handles to depots and PStates. Depots and PStates are identified by their module name (the class name of the module definition) and their name within the module. By default, depot appends block until all colocated streaming topologies have finished processing the appended data. This is why the PState queries can be executed immediately following the depot appends without further coordination.
The PState queries here fetch the values for the specified keys. PStates are queried using Rama’s “Path” API, and this example barely scratches the surface of what you can do with paths. They allow you to easily reach into a PState, regardless of its structure, and retrieve precisely what you need – whether one value, multiple values, or an aggregation of values. They can also be used for updating PStates within topologies. Mastering paths is one of the keys to mastering Rama development.
Let’s now take a look at how you would run
WordCountModule
in a unit test environment:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | public void wordCountTest() throws Exception { try (InProcessCluster cluster = InProcessCluster.create()) { cluster.launchModule(new WordCountModule(), new LaunchConfig(4, 2)); String moduleName = WordCountModule.class.getName(); Depot depot = cluster.clusterDepot(moduleName, "*sentenceDepot"); depot.append("hello world"); depot.append("hello world again"); depot.append("say hello to the planet"); depot.append("red planet labs"); PState wc = cluster.clusterPState(moduleName, "$$wordCounts"); System.out.println("'hello' count: " + wc.selectOne(Path.key("hello"))); System.out.println("'world' count: " + wc.selectOne(Path.key("world"))); System.out.println("'planet' count: " + wc.selectOne(Path.key("planet"))); System.out.println("'red' count: " + wc.selectOne(Path.key("red"))); } } |
Running this code prints:
1 2 3 4 | 'hello' count: 3 'world' count: 2 'planet' count: 2 'red' count: 1 |
InProcessCluster
simulates a Rama cluster completely in-process and is ideal for unit testing modules. Here you can see how
InProcessCluster
is used to launch the module and then fetch depots/PStates just like with
RamaClusterManager
. There’s no difference in the functionality available with
InProcessCluster
versus a real cluster, and you’ll be able to try out
InProcessCluster
next week when we release the non-production build of Rama.
Sample code from our Mastodon implementation
Now let’s look at some code from our Mastodon implementation. We’ll be looking at bigger code samples in this section utilizing a lot more of the Rama API, so even more than the last section I won’t be able to explain all the details of the code. I’ll summarize what the key parts are, and you’ll be able to learn all the details next week when we release the documentation.
Please don’t be too intimidated by this code. There are a lot of concepts and API methods at work here, and no one could possibly understand this code completely at a first glance. This is especially true without the accompanying documentation. I’m showing this code because it ties together the high-level concepts I’ve discussed in this post by making them real instead of abstract.
Representing data
Let’s start by looking at an example of how data is defined. We chose to represent data using Thrift since it has a nice schema definition language and produces efficient serialization, but you can just as easily use plain Java objects, Protocol Buffers, or anything else you want. We use Thrift-defined objects in both depots and PStates. Here’s how statuses are defined:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 | typedef i64 AccountId typedef i64 StatusId typedef i64 Timestamp enum StatusVisibility { Public = 1, Unlisted = 2, Private = 3, Direct = 4 } enum AttachmentKind { Image = 1, Video = 2 } struct StatusPointer { 1: required AccountId authorId; 2: required StatusId statusId; 3: optional Timestamp timestamp; 4: optional bool shouldExclude; } struct PollContent { 1: list<string> choices; 2: required Timestamp expiration; 3: required bool multipleChoice; } struct Attachment { 1: required AttachmentKind kind; 2: required string extension; 3: required string description; } struct AttachmentWithId { 1: required string uuid; 2: required Attachment attachment; } struct NormalStatusContent { 1: required string text; 2: required StatusVisibility visibility; 3: optional PollContent pollContent; 4: optional list<AttachmentWithId> attachments; 5: optional string sensitiveWarning; } struct ReplyStatusContent { 1: required string text; 2: required StatusVisibility visibility; 3: required StatusPointer parent; 4: optional PollContent pollContent; 5: optional list<AttachmentWithId> attachments; 6: optional string sensitiveWarning; } struct BoostStatusContent { 1: required StatusPointer boosted; } union StatusContent { 1: NormalStatusContent normal; 2: ReplyStatusContent reply; 3: BoostStatusContent boost; } struct Status { 1: required AccountId authorId; 2: required StatusContent content; 3: required Timestamp timestamp; 4: optional string remoteUrl; 5: optional string language; } |
Every type of status, including boosts, replies, and statuses with polls is represented by this definition. Being able to represent your data using normal programming practices, as opposed to restrictive database environments where you can’t have nested definitions like this, goes a long way in avoiding impedance mismatches and keeping code clean and comprehensible.
Following hashtags code
Next, let’s look at the entire definition of following hashtags (described earlier in this post). As a reminder, here’s the dataflow diagram for the following hashtags ETL:

Here’s the implementation, which is a direct translation of the diagram to code:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | setup.declareDepot("*followHashtagDepot", Depot.hashBy(ExtractToken.class)); StreamTopology stream = topologies.stream("relationshipsStream"); stream.pstate("$$hashtagToFollowers", PState.mapSchema(String.class, PState.setSchema(Long.class).subindexed())); stream.source("*followHashtagDepot", StreamSourceOptions.retryAllAfter()).out("*data") .subSource("*data", SubSource.create(FollowHashtag.class) .macro(extractFields("*data", "*accountId", "*token")) .localTransform("$$hashtagToFollowers", Path.key("*token").voidSetElem().termVal("*accountId")), SubSource.create(RemoveFollowHashtag.class) .macro(extractFields("*data", "*accountId", "*token")) .localTransform("$$hashtagToFollowers", Path.key("*token").setElem("*accountId").termVoid())); |
This is extremely simple.
subSource
branches the dataflow graph based on the type of an object. In this code the object in
*data
can be one of two types, and there is a separate branch of dataflow for each type. When a
FollowHashtag
event is received, that account is added to the set of followers for that hashtag. When a
RemoveFollowHashtag
event is received, that account is removed from the set of followers for that hashtag. Because the nested sets are subindexed, they can efficiently contain hundreds of millions of elements or more.
extractFields
is a helper function in the Mastodon implementation for extracting fields out of Thrift objects by name and binding them to corresponding Rama variables of the same name. So
extractFields("*data", "*accountId", "*token"))
extracts the fields “accountId” and “token” from the Thrift object in
*data
and binds them to the variables
*accountId
and
*token
.
extractFields
is implemented as a Rama macro, which is a utility for inserting a snippet of dataflow code into another section of dataflow code. It is a mechanism for code reuse that allows the composition of any dataflow elements: functions, filters, aggregation, partitioning, etc.
Unlike word count, this code uses paths instead of aggregators to define the writes to the PStates, which is the same API used to read from PStates. You’ll be able to learn more next week when we release Rama’s documentation about the differences between aggregators and paths and when to prefer one over the other.
Note that this code defines a parallel computation just like the word count example earlier. The code runs across many nodes to process data off each partition of the depot and update the PState. Any failures (e.g. a node dying) are handled transparently and Rama guarantees all depot data will be fully processed.
The partitioning is defined at the depot level (
Depot.hashBy(ExtractToken.class)
), so when the ETL begins processing a piece of data, the computation is already located on the partition of the module storing followers for that hashtag. So no further partitioning is needed in the ETL definition.
Social graph code
Next, let’s look at the entire definition of the social graph as described earlier. Here was the dataflow diagram for the social graph ETL:

Like hashtag follows, the social graph implementation is also a direct translation of the diagram to code. Since the code for this is longer, let’s look at it section by section in the order in which it’s written. The first part is the declaration of the depots, topology, and PStates:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | setup.declareDepot("*followAndBlockAccountDepot", Depot.hashBy(ExtractAccountId.class)); setup.declareDepot("*muteAccountDepot", Depot.hashBy(ExtractAccountId.class)); StreamTopology stream = topologies.stream("relationshipsStream"); KeyToLinkedEntitySetPStateGroup accountIdToFollowRequests = new KeyToLinkedEntitySetPStateGroup("$$accountIdToFollowRequests", Long.class, FollowLockedAccount.class) .entityIdFunction(Long.class, req -> ((FollowLockedAccount) req).requesterId) .descending(); accountIdToFollowRequests.declarePStates(stream); KeyToLinkedEntitySetPStateGroup followerToFollowees = new KeyToLinkedEntitySetPStateGroup("$$followerToFollowees", Long.class, Follower.class) .entityIdFunction(Long.class, new ExtractAccountId()) .descending(); KeyToLinkedEntitySetPStateGroup followeeToFollowers = new KeyToLinkedEntitySetPStateGroup("$$followeeToFollowers", Long.class, Follower.class) .entityIdFunction(Long.class, new ExtractAccountId()) .descending(); followerToFollowees.declarePStates(stream); followeeToFollowers.declarePStates(stream); stream.pstate("$$accountIdToSuppressions", PState.mapSchema(Long.class, PState.fixedKeysSchema("muted", PState.mapSchema(Long.class, MuteAccountOptions.class).subindexed(), "blocked", PState.setSchema(Long.class).subindexed()))); |
Note that both hashtag follows and the social graph are part of the same stream topology. The social graph implementation consumes different depots than hashtag follows does, so the code is otherwise completely independent.
The
$$followerToFollowees
and
$$followeeToFollowers
PStates are defined with
KeyToLinkedEntitySetPStateGroup
, which defines the “map to linked set” data structure abstraction as the composition of multiple, more primitive PStates underneath the hood. Its implementation is only 68 lines of code.
The next part defines the root of processing where the branching occurs at the start of the dataflow diagram:
1 2 | stream.source("*followAndBlockAccountDepot", StreamSourceOptions.retryAllAfter()).out("*initialData") .anchor("SocialGraphRoot") |
As we build up the code for the social graph, let’s also take a look visually at how the dataflow diagram is filled out. This code starts off the dataflow diagram like this:

anchor
defines a location in a dataflow graph that can later be hooked onto with
hook
. The next section defines the first branch of processing:
1 2 | .each(Ops.IDENTITY, "*initialData").out("*data") .anchor("Normal") |

This branch passes all data through to the anchor “Normal”, which will later be merged with other branches as you can see in the dataflow diagram.
Rama provides the
Ops
class which has commonly used functions to use within dataflow code. This includes math operations, comparators, and other utilities. Here
Ops.IDENTITY
is used which emits its input unchanged.
The next section defines the branch handling implicit unfollow events for block events:
1 2 3 4 5 6 7 8 | .hook("SocialGraphRoot") .keepTrue(new Expr(Ops.IS_INSTANCE_OF, BlockAccount.class, "*initialData")) .each((BlockAccount data, OutputCollector collector) -> { collector.emit(new RemoveFollowAccount(data.getAccountId(), data.getTargetId(), data.getTimestamp())); collector.emit(new RemoveFollowAccount(data.getTargetId(), data.getAccountId(), data.getTimestamp())); collector.emit(new RejectFollowRequest(data.getAccountId(), data.getTargetId())); }, "*initialData").out("*data") .anchor("ImplicitUnfollow") |

This uses
hook
to create a branch off the root of processing for this depot that was defined in the previous code section. The
keepTrue
line continues processing on this branch only for block events. It then generates implicit events to unfollow in both directions and remove a follow request if it exists. Lastly, the “ImplicitUnfollow” anchor is declared which will later be used to merge this branch together with “Normal” and other branches.
The next section defines the branch handling accepting a follow request:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | .hook("SocialGraphRoot") .keepTrue(new Expr(Ops.IS_INSTANCE_OF, AcceptFollowRequest.class, "*initialData")) .macro(extractFields("*initialData", "*accountId", "*requesterId")) .localSelect("$$accountIdToFollowRequests", Path.key("*accountId").must("*requesterId")).out("*followRequestId") .localSelect("$$accountIdToFollowRequestsById", Path.key("*accountId", "*followRequestId")).out("*followRequest") .hashPartition("*requesterId") .each((AcceptFollowRequest data, FollowLockedAccount req) -> { FollowAccount follow = new FollowAccount(data.getRequesterId(), data.getAccountId(), data.getTimestamp()); if (req.isSetShowBoosts()) follow.setShowBoosts(req.showBoosts); if (req.isSetNotify()) follow.setNotify(req.notify); if (req.isSetLanguages()) follow.setLanguages(req.languages); return follow; } , "*initialData", "*followRequest").out("*data") .anchor("CompleteFollowRequest") |

This code is structured just like the previous sections by hooking onto the root and then filtering for the data type of interest. Then, this code checks to see if that follow request still exists since a user could retract their follow request at the same time it was accepted. The
must
navigator stops this branch of computation if the follow request no longer exists.
After that, the code generates the implicit
Follow
event which will later perform the actual logic of updating the
$$followerToFollowees
and
$$followeeToFollowers
PStates.
The next section handles follows to a locked account. As a reminder, a locked account requires all followers to be manually approved.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | .hook("SocialGraphRoot") .keepTrue(new Expr(Ops.IS_INSTANCE_OF, FollowLockedAccount.class, "*initialData")) .macro(extractFields("*initialData", "*accountId", "*requesterId")) .localSelect("$$followeeToFollowers", Path.key("*accountId", "*requesterId")).out("*existingFollowerId") .ifTrue(new Expr(Ops.IS_NOT_NULL, "*existingFollowerId"), Block.each((FollowLockedAccount data) -> { FollowAccount follow = new FollowAccount(data.requesterId, data.accountId, data.timestamp); if(data.isSetShowBoosts()) follow.setShowBoosts(data.isShowBoosts()); if(data.isSetNotify()) follow.setNotify(data.isNotify()); if(data.isSetLanguages()) follow.setLanguages(data.getLanguages()); return follow; }, "*initialData").out("*data") .hashPartition("*requesterId") .anchor("UpdatePrivateFollow"), Block.macro(extractFields("*initialData", "*accountId", "*requesterId")) .macro(accountIdToFollowRequests.addToLinkedSet("*accountId", "*initialData"))) |

When a follow request is done in the UI to a locked account, a
FollowLockedAccount
event is appended to the depot. Otherwise, a
FollowAccount
event is appended.
Follow relationships contain additional information such as whether the follower wants to see boosts from the followee and whether they only want to see statuses in a certain language from the followee (another one of Mastodon’s features). Updating these settings is done via another
Follow
or
FollowLockedAccount
event.
This code uses
ifTrue
to determine if the follower already follows the followee.
ifTrue
works just like
if
in any programming language, with a “then” block and an optional “else” block. If the follow relationship exists, it creates an implicit
FollowAccount
event to update the options on the relationship. The “UpdatePrivateFollow” anchor is used later to merge that branch just like the previous sections.
If the follow relationship does not already exist, then the PState tracking follow requests is updated.
The next section merges the prior branches together and begins processing for the rest of the events, whether they came directly off the depot or were created implicitly by one of the branches:
1 2 | .unify("Normal", "ImplicitUnfollow", "CompleteFollowRequest", "UpdatePrivateFollow") .subSource("*data", |

unify
merges the specified branches together so they share subsequent computation. Any variables that are in scope in all specified branches are in scope in the code following the
unify
call.
The
subSource
call dispatches subsequent code on the type of the object in
*data
. The following code defines the handling for
FollowAccount
events:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | SubSource.create(FollowAccount.class) .macro(extractFields("*data", "*accountId", "*targetId", "*followerSharedInboxUrl", "*showBoosts", "*notify", "*languages")) .localSelect("$$followerToFollowees", Path.key("*accountId").view(Ops.SIZE)).out("*followeeCount") .keepTrue(new Expr(Ops.LESS_THAN, "*followeeCount", relationshipCountLimit)) .localSelect("$$followerToFollowees", Path.key("*accountId", "*targetId")).out("*followeeId") .localSelect("$$followerToFolloweesById", Path.key("*accountId", "*followeeId")).out("*existingFollowee") .each(Relationships::makeFollower, "*targetId", "*showBoosts", "*languages", "*followerSharedInboxUrl", "*existingFollowee").out("*followee") .macro(followerToFollowees.addToLinkedSet("*accountId", "*followee")) .hashPartition("*targetId") .localSelect("$$followeeToFollowers", Path.key("*targetId", "*accountId")).out("*followerId") .localSelect("$$followeeToFollowersById", Path.key("*targetId", "*followerId")).out("*existingFollower") .each(Relationships::makeFollower, "*accountId", "*showBoosts", "*languages", "*followerSharedInboxUrl", "*existingFollower").out("*follower") .macro(followeeToFollowers.addToLinkedSet("*targetId", "*follower")) .macro(accountIdToFollowRequests.removeFromLinkedSetByEntityId("*targetId", "*accountId")), |

This code adds the relationship to the
$$followerToFollowees
and
$$followerToFollowees
PStates. If the relationship already exists, it updates the options on the relationship. It also removes any corresponding follow request from
$$accountIdToFollowRequests
if it exists.
relationshipCountLimit
puts an upper limit on the number of follows someone can have and is set to a very conservative limit of 100,000. It exists to prevent abuse of the system.
The next section handles
RemoveFollowAccount
events:
1 2 3 4 5 6 7 | SubSource.create(RemoveFollowAccount.class) .macro(extractFields("*data", "*accountId", "*targetId", "*followerSharedInboxUrl")) .hashPartition("*accountId") .macro(followerToFollowees.removeFromLinkedSetByEntityId("*accountId", "*targetId")) .hashPartition("*targetId") .macro(followeeToFollowers.removeFromLinkedSetByEntityId("*targetId", "*accountId")) .macro(accountIdToFollowRequests.removeFromLinkedSetByEntityId("*targetId", "*accountId")), |

This code just removes the relationship from all relevant PStates.
Here is the next section:
1 2 3 | SubSource.create(FollowLockedAccount.class), SubSource.create(AcceptFollowRequest.class), |
This handles events coming off the depot that were handled already in one of the top-level branches we already looked at.
subSource
requires every data type it sees to have a handler, so this code says to do nothing for those types.
The next section handles
RejectFollowRequest
:
1 2 3 | SubSource.create(RejectFollowRequest.class) .macro(extractFields("*data", "*accountId", "*requesterId")) .macro(accountIdToFollowRequests.removeFromLinkedSetByEntityId("*accountId", "*requesterId")), |

This just removes the follow request from the PState.
The next section handles
BlockAccount
:
1 2 3 4 5 | SubSource.create(BlockAccount.class) .macro(extractFields("*data", "*accountId", "*targetId", "*timestamp")) .localSelect("$$accountIdToSuppressions", Path.key("*accountId", "blocked").view(Ops.SIZE)).out("*blockeeCount") .keepTrue(new Expr(Ops.LESS_THAN, "*blockeeCount", relationshipCountLimit)) .localTransform("$$accountIdToSuppressions", Path.key("*accountId", "blocked").voidSetElem().termVal("*targetId")), |

BlockAccount
was handled in one of the initial branches to generate the implicit unfollows between the two accounts. Here,
BlockAccount
is handled again to record the block relationship in the
$$accountIdToSuppressions
PState.
The next section handles
RemoveBlockAccount
events:
1 2 3 | SubSource.create(RemoveBlockAccount.class) .macro(extractFields("*data", "*accountId", "*targetId")) .localTransform("$$accountIdToSuppressions", Path.key("*accountId", "blocked").setElem("*targetId").termVoid())); |

All this does is remove the block relationship from the
$$accountIdToSuppressions
PState.
That’s all the code for handling social graph updates from events on
followAndBlockAccountDepot
. The next section contains all the logic for handling events from
muteAccountDepot
:
1 2 3 4 5 6 7 8 9 10 | stream.source("*muteAccountDepot", StreamSourceOptions.retryAllAfter()).out("*data") .subSource("*data", SubSource.create(MuteAccount.class) .macro(extractFields("*data", "*accountId", "*targetId", "*options")) .localSelect("$$accountIdToSuppressions", Path.key("*accountId", "muted").view(Ops.SIZE)).out("*muteeCount") .keepTrue(new Expr(Ops.LESS_THAN, "*muteeCount", relationshipCountLimit)) .localTransform("$$accountIdToSuppressions", Path.key("*accountId", "muted", "*targetId").termVal("*options")), SubSource.create(RemoveMuteAccount.class) .macro(extractFields("*data", "*accountId", "*targetId")) .localTransform("$$accountIdToSuppressions", Path.key("*accountId", "muted", "*targetId").termVoid())); |

This is really simple, as all it does is add the mute relationship for
MuteAccount
events and remove the relationship for
RemoveMuteAccount
events.
That’s the complete implementation of the social graph! As you can see, it’s expressed exactly as you saw in the dataflow diagram with branches, merges, and dispatching on the types of events.
It’s worth noting that dataflow code compiles to efficient bytecode when deployed, as efficient as regular Java code. So Rama variables like
*accountId
and
*targetId
become actual variables in the generated bytecode.
The code for this ETL is also a great example of why it’s so beneficial to interact with your data layer with an API in a general-purpose language instead of a custom language (like SQL). This code makes use of normal programming practices to factor out reusable functionality or to separate code into separate functions to make it easier to read. This code also demonstrates how easy it is to intermix logic written in Java with logic written in Rama’s dataflow API. Method references, lambdas, and macros are facilities for combining the two.
Let’s look at some of the Mastodon API implementation related to the social graph so you can see how you interact with a Rama cluster to serve the frontend. Here’s how a new unfollow event is added:
1 2 3 4 5 | public CompletableFuture<Boolean> postRemoveFollowAccount(long followerId, long followeeId, String sharedInboxUrl) { RemoveFollowAccount removeFollowAccount = new RemoveFollowAccount(followerId, followeeId, System.currentTimeMillis()); if (sharedInboxUrl != null) removeFollowAccount.setFollowerSharedInboxUrl(sharedInboxUrl); return followAndBlockAccountDepot.appendAsync(removeFollowAccount).thenApply(res -> true); } |
This uses the async API for depots to append unfollow data to
followAndBlockAccountDepot
. Rama’s async API is used almost exclusively in the Mastodon API implementation so as not to block any threads (which would be an inefficient use of resources).
Here’s how a follow event is handled, conditioning the type of data appended depending on if the account is locked or not:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | public CompletableFuture<Boolean> postFollowAccount(long followerId, long followeeId, String sharedInboxUrl, PostFollow params) { return getAccountWithId(followeeId) .thenCompose((followee) -> { if (followee != null && followee.account != null && followee.account.locked) { FollowLockedAccount req = new FollowLockedAccount(followeeId, followerId, System.currentTimeMillis()); if (params != null) { if (params.reblogs != null) req.setShowBoosts(params.reblogs); if (params.notify != null) req.setNotify(params.notify); if (params.languages != null) req.setLanguages(params.languages); } return followAndBlockAccountDepot.appendAsync(req); } else { FollowAccount req = new FollowAccount(followerId, followeeId, System.currentTimeMillis()); if (params != null) { if (params.reblogs != null ) req.setShowBoosts(params.reblogs); if (params.notify != null) req.setNotify(params.notify); if (params.languages != null) req.setLanguages(params.languages); } if (sharedInboxUrl != null) req.setFollowerSharedInboxUrl(sharedInboxUrl); return followAndBlockAccountDepot.appendAsync(req); } }).thenApply(res -> true); } |
This first calls the helper function
getAccountWithId
which uses a query topology to get all information about that account. If the account is locked, a
FollowLockedAccount
is appended with any options appropriately set. Otherwise, a
FollowAccount
events is appended.
The helper function
getAccountWithId
is implemented like this:
1 2 3 4 5 6 7 8 9 10 11 | public CompletableFuture<AccountWithId> getAccountWithId(Long requestAccountIdMaybe, long accountId) { return getAccountsFromAccountIds.invokeAsync(requestAccountIdMaybe, Arrays.asList(accountId)) .thenApply(accounts -> { if (accounts.size() == 0) return null; return accounts.get(0); }); } public CompletableFuture<AccountWithId> getAccountWithId(long accountId) { return this.getAccountWithId(null, accountId); } |
The query topology can optionally be invoked with a “requesting account ID”, because in some circumstances an account should not be visible to another account (e.g. the requesting account is blocked by that user). In this case, it just needs to check if the account is locked or not so it passes
null
for the requesting account ID. The query topology client is fetched like so:
1 | QueryTopologyClient<List> getAccountsFromAccountIds = cluster.clusterQuery("com.rpl.mastodon.modules.Core", "getAccountsFromAccountIds"); |
As you can see, a query topology client is fetched just like how you fetch a handle to a depot or PState. Invoking a query topology is like invoking a regular function – you pass it some arguments and you get a result back. Unlike a regular function, a query topology executes on a cluster across potentially many nodes. Here the result is received asynchronously, but you can also do a blocking call with
invoke
.
Timeline fanout code
Lastly, let’s look at the code implementing timeline fanout, as described earlier. This implementation is only 51 lines of code. As a reminder, here’s the dataflow diagram for timeline fanout:

Once again, since this is a longer piece of code let’s look at it section by section. Let’s start with the subscription to the depot containing all the statuses:
1 2 | fan.source("*statusWithIdDepot").out("*microbatch") .anchor("FanoutRoot") |
Like in the social graph example, let’s see visually how the dataflow diagram gets filled out. This code starts off the dataflow diagram like this:

Unlike the previous examples, this topology is implemented with microbatching. Microbatching guarantees exactly-once processing semantics even in the case of failures. That is, even if there are node or network outages and computation needs to be retried, the resulting PState updates will be as if each depot record was processed exactly once.
The variable
*microbatch
represents a batch of data across all partitions of the depot. This code simply binds that variable and marks the root of computation with the label “FanoutRoot”. As you can see in the dataflow diagram, there are two branches off the root of processing.
The next section implements the first branch, which handles continuing fanout for statuses with too many followers from the previous iteration:
1 2 3 4 5 6 7 8 9 10 11 | .allPartition() .localSelect("$$statusIdToLocalFollowerFanouts", Path.all()).out("*keyAndVal") .each(Ops.EXPAND, "*keyAndVal").out("*statusId", "*followerFanouts") .localTransform("$$statusIdToLocalFollowerFanouts", Path.key("*statusId").termVoid()) .each(Ops.EXPLODE, "*followerFanouts").out("*followerFanout") .macro(extractFields("*followerFanout", "*authorId", "*nextIndex", "*fanoutAction", "*status", "*task")) .each(FanoutAction::getValue, "*fanoutAction").out("*fanoutActionValue") .macro(extractFields("*status", "*content", "*language")) .each((RamaFunction2<Long, Long, StatusPointer>) StatusPointer::new, "*authorId", "*statusId").out("*statusPointer") .directPartition("$$partitionedFollowers", "*task") .anchor("LocalFollowerFanoutContinue") |

Whenever a status has too many followers for one iteration of fanout, it is added to the
$$statusIdToLocalFollowerFanouts
PState. This PState is a map from status ID to the type
FollowerFanout
, which contains the information needed to continue fanout starting with the next unhanded follower. As you can see in this code, it reads everything from that PState using
Path.all()
and then deletes everything from that PState.
As you’ll see later, adding to
$$statusIdToLocalFollowerFanouts
is done on whatever partition followers were read for that status. So this code uses
allPartition
to access every partition of the PState.
allPartition
is a partitioner like
hashPartition
, except instead of the subsequent code executing on one partition, the subsequent code executes on all partitions. This allows the ETL to fetch all statuses that required continued fanout from the last iteration. You have to be careful when using
allPartition
as you can create non-scalable topologies if you were to use it for every piece of data on a high throughput depot. In this case
allPartition
is used just once per iteration, so it doesn’t affect the scalability of the topology.
At the end of this block of code is some handling related to
$$partitionedFollowers
. We didn’t mention this PState in the earlier discussion of fanout, but it’s an additional optimization to balance load for handling of users with large amounts of followers. In short, this is an additional view of the social graph where users with more than 1,000 followers have their followers spread among multiple partitions of this PState. This balances the load of processing for fanout by reducing variance among partitions. We will be publishing another blog post in the future exploring this optimization and others.
The next section begins the other branch of processing at the root of the dataflow diagram:
1 2 | .hook("FanoutRoot") .explodeMicrobatch("*microbatch").out("*data") |
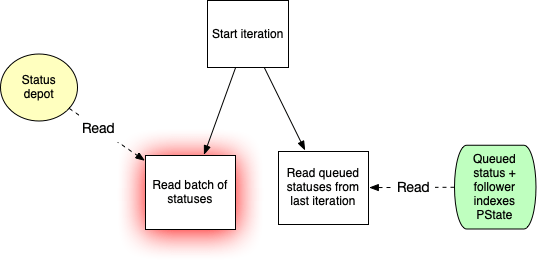
This creates the branch and reads all new statuses for this iteration from the microbatch.
explodeMicrobatch
here reads all data from the microbatch across all partitions and binds each piece of data to the variable
*data
. This operation emits across all partitions of the module.
The next section begins processing of new statuses:
1 2 3 4 5 6 7 8 | .macro(extractFields("*data", "*statusId", "*status")) .macro(extractFields("*status", "*authorId", "*content", "*language")) .each(MastodonHelpers::getStatusVisibility, "*status").out("*visibility") .keepTrue(new Expr(Ops.NOT_EQUAL, "*visibility", StatusVisibility.Direct)) .each(Ops.IDENTITY, -1L).out("*nextIndex") .each(Ops.IDENTITY, FanoutAction.Add.getValue()).out("*fanoutActionValue") .each((RamaFunction2<Long, Long, StatusPointer>) StatusPointer::new, "*authorId", "*statusId").out("*statusPointer") .each(HomeTimelines::addTimelineItem, "*homeTimelines", "*authorId", "*statusPointer", new Expr(Ops.CURRENT_MICROBATCH_ID)) |

This code specifies to only perform fanout for statuses with visibility other than
Direct
, which is for direct messages and handled elsewhere. It then adds the status to the author’s own home timeline, which implements self-fanout.
The next section reads a batch of followers for the status:
1 2 3 4 5 6 7 8 9 10 | .select("$$partitionedFollowersControl", Path.key("*authorId")).out("*tasks") .each(Ops.EXPLODE_INDEXED, "*tasks").out("*i", "*task") .ifTrue(new Expr(Ops.NOT_EQUAL, 0, "*i"), Block.directPartition("$$partitionedFollowers", "*task")) .anchor("NormalFanout") .unify("NormalFanout", "LocalFollowerFanoutContinue") .macro(safeFetchMapLocalFollowers("$$partitionedFollowers", "*authorId", "*nextIndex", rangeQueryLimit, "*fetchedFollowers", "*nextFollowerId")) .ifTrue(new Expr(Ops.IS_NOT_NULL, "*nextFollowerId"), Block.each((RamaFunction5<Long, Long, FanoutAction, Status, Integer, FollowerFanout>) FollowerFanout::new, "*authorId", "*nextFollowerId", new Expr(FanoutAction::findByValue, "*fanoutActionValue"), "*status", "*task").out("*followerFanout") .localTransform("$$statusIdToLocalFollowerFanouts", Path.key("*statusId").nullToList().afterElem().termVal("*followerFanout"))) |

As mentioned earlier, in a future post we’ll explore the
$$partitionedFollowers
optimization. As will be explored in that future post, the first section of this code determines from which tasks to read followers in parallel for the status’s author.
The
unify
call merges processing for statuses from both last iteration and new statuses from this iteration.
safeFetchMapLocalFollowers
is a small helper function reading up to
rangeQueryLimit
followers from this partition for that author (
rangeQueryLimit
is a constant set to 1,000). Since followers are read in parallel across many partitions for users with more than 1,000 followers, and since we deployed this module with 64 partitions, this means up to 64k followers are read per status per iteration.
The
ifTrue
line writes to the
$$statusIdToLocalFollowerFanouts
PState to continue fanout next iteration if there are still more followers to handle. This is the same PState you saw used in the earlier section.
The next section handles follower-specified options on the types of statuses they wish to see from this author:
1 2 3 4 5 6 7 8 9 10 11 | .each(Ops.EXPLODE, "*fetchedFollowers").out("*follower") .each((Follower follower) -> follower.accountId, "*follower").out("*followerId") .each((Follower follower) -> follower.sharedInboxUrl, "*follower").out("*followerSharedInboxUrl") .each((Follower follower) -> follower.isShowBoosts(), "*follower").out("*showBoosts") .each((Follower follower) -> follower.getLanguages(), "*follower").out("*languages") .keepTrue(new Expr(Ops.IS_NULL, "*followerSharedInboxUrl")) // skip remote followers .ifTrue(new Expr(Ops.IS_INSTANCE_OF, BoostStatusContent.class, "*content"), Block.macro(extractFields("*content", "*boostedAuthorId")) .keepTrue(new Expr(Ops.NOT_EQUAL, "*boostedAuthorId", "*followerId")) .keepTrue("*showBoosts")) .keepTrue(new Expr((List<String> languages, String statusLanguage) -> languages == null || statusLanguage == null || languages.contains(statusLanguage), "*languages", "*language")) |

This filters this follower out of fanout for this status if: it’s a boost and they don’t wish to see boosts from this author, it’s a boost and they’re the original author of the status, or they specified they only wish to see certain languages from this author and the status doesn’t match.
Notice how all the information needed to do the filtering is on the
Follower
structure that was retrieved as part of fetching followers for fanout. No extra PState queries need to be done for this information, which is one of the reasons our implementation has such high throughput. The average amount of fanout per status on our instance is 403, so any work post-fanout (after the
Ops.EXPLODE
call, which emits once per follower in the
*fetchedFollowers
list) is multiplied by 403 compared to work pre-fanout. This is why we went out of our way to materialize as much information on the follow relationship as possible to minimize the work post-fanout.
The next section handles additional filtering required for replies:
1 2 3 4 5 6 | .ifTrue(new Expr(Ops.IS_INSTANCE_OF, ReplyStatusContent.class, "*content"), Block.macro(extractFields("*content", "*parentAuthorId")) .hashPartition("*followerId") .macro(fetchBloomMacro("*followerId", "*rbloom")) .keepTrue(new Expr((RBloomFilter rbloom, Long accountId) -> rbloom.bloom.isPresent("" + accountId), "*rbloom", "*parentAuthorId")) .select("$$followerToFollowees", Path.key("*followerId").must("*parentAuthorId"))) |

Replies are delivered to a follower only if they also follow the account being replied to. This code queries
$$followerToFollowees
to perform that check, with the
must
navigator only emitting if the follow relationship exists.
Before the PState query, there’s a bloom filter check to minimize the amount of PState queries done here. This is another optimization that we didn’t mention in the earlier discussion of fanout, and we’ll discuss it more in a future post. In short, a bloom filter is materialized and cached in-memory on this module for each account with all follows for the account. If the bloom filter returns false, the follow relationship definitely does not exist and no PState query is necessary. If it returns true, the PState query is done to weed out false positives. The bloom filter reduces PState queries for replies by 99%.
The next section completes this ETL by writing to the home timelines of followers that have passed each of the preceding filters:
1 2 | .hashPartition("*followerId") .each(HomeTimelines::addTimelineItem, "*homeTimelines", "*followerId", "*statusPointer", new Expr(Ops.CURRENT_MICROBATCH_ID)); |

This simply routes to the appropriate partition hosting each follower’s home timeline and then adds to it. That
.hashPartition
call is actually the most expensive part of this ETL because of the huge volume of messages that flow through it. Due to the average of 403 fanout on our instance and our incoming rate of 3,500 statuses / second, 1.4M messages go across that partitioner every second.
When we open-source our Mastodon instance in two weeks, you’ll see that this ETL also handles hashtags, lists, conversations, and federation. We excluded those from this code example since they’re all pretty similar to home timeline fanout, with slightly different rules. They’re just additional branches of computation on this ETL.
That’s all we’ll show for now. As mentioned, in two weeks we’ll be open-sourcing our entire Mastodon implementation.
Conclusion
I’ve covered a lot in this post, but I’ve barely scratched the surface on Rama and our Mastodon implementation. For example, I didn’t mention “fine-grained reactivity”, a new capability provided by Rama that’s never existed before. It allows for true incremental reactivity from the backend up through the frontend. Among other things it will enable UI frameworks to be fully incremental instead of doing expensive diffs to find out what changed. We use reactivity in our Mastodon implementation to power much of Mastodon’s streaming API.
I also didn’t mention Rama’s integration API. Because of my description of Rama as being able to build an entire backend on its own, you may have the impression that Rama is an “all-or-nothing” tool. However, just because Rama can do so much doesn’t mean it has to be used to do everything. We’ve designed Rama to be able to seamlessly integrate with any other tool (e.g. databases, queues, monitoring systems, etc.). This allows Rama to be introduced gradually into any architecture.
To reiterate what’s to come: in one week we will be releasing the full Rama documentation as well as a build of Rama that exposes the full API for use with
InProcessCluster
, and in two weeks we will be fully open-sourcing our Mastodon implementation (which can run on
InProcessCluster
). Additionally, we will be publishing more posts exploring Rama and our Mastodon implementation in greater depth.
You can keep track of developments with Rama by joining our newsletter or following us on Twitter at @redplanetlabs. We’ve also started the Google group rama-user, where you can discuss Rama or ask questions.
Lastly, Red Planet Labs will be starting a private beta in the coming months to give companies access to the full version of Rama. We plan to work closely with our private beta users to help them build new systems or reimplement existing systems at massively reduced cost. We will be releasing more details on the private beta later, but you can apply here in the meantime.
10 years after: the style is seamlessly-like reading the follow-up to Manning’s “Big Data” book. This is one of the most significant technical books I have read (thank you).
You’re welcome!
amazing!!
Thank you for sharing the article. I think, Rama seems to be the generalized platform of implementation of lambda architecture you, Nathan created. And Rama module api codes look similar to Storm. Great work!
– Kidong Lee
The Lambda Architecture was indeed a big part of designing Rama. Rama hasn’t generalized all of it yet, but we have more planned for the future.
Though the API may share some similarities with Storm, the computation capabilities of Rama are far greater.
I wondered what you had been up to. Storm was impressive and then blink, you had disappeared. Rama’s pretty amazing, I’m looking forward to see how it unfolds.
Haven’t read through all the details yet but quite intrigued by the system design I see here. Large scale systems are mostly collections of a variety of hand coded ad-hoc “local views” and “local models”, all derived from the same set of data. This happens at different layers, different granularity for various performance and other reasons. Unifying withing a single “system wide model” sounds like a big step in the right direction. Assuming this can take care of performance and other concerns also (which is what you’re trying to show above I suppose), this can be very compelling.
A followup discussing how to do version/schema/logic upgrades in place would be good. Once the system is running for a year or two at that scale, introducing changes and how to handle backfill etc would be interesting. Schema changes must be forwards compatible or is there a scheme under the covers to smooth that?
Will definitely do a followup post on this topic. When we release the documentation next week, you’ll be able to learn more about “module update”, which is the mechanism for updating the logic/depots/PStates of a currently running module.
We currently have a project in flight to add “migrations” to module update, which will let you change schemas in backwards-incompatible ways and/or restructure PStates.
What a great read! The dataflow programming DSL **feels** like a tough sell to devs who hasn’t worked with big data before though. A bit more details on resilience will also be great, such as error handling, disaster recovery, backup etc.
We have tons of detail on that in the Rama documentation: https://redplanetlabs.com/docs/~/index.html
Check out the pages on stream topologies, microbatch topologies, and replication.